9 Steps of Data Science Lifecycle With Challenges: Deep Dive

The vast expanse of data lies the potential to unlock profound insights, drive innovation, and propel organizations into the future. Often likened to magic, data science is a systematic and enchanting journey that transforms raw, seemingly chaotic data into actionable knowledge.
In this blog, we explore the Data Science Lifecycle—a spellbinding sequence of steps that unveils the secrets hidden within data and empowers decision-makers to wield the wand of informed choices.
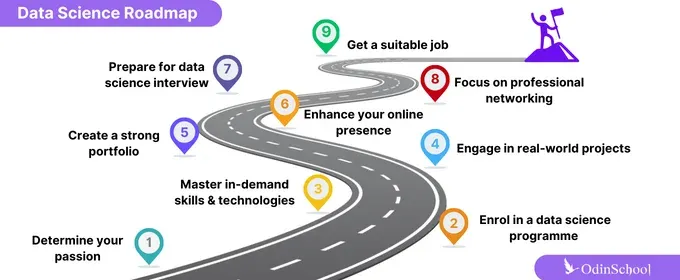
What is a Data Science Lifecycle?
The Data Science Lifecycle refers to the systematic process or set of stages that data scientists follow to extract meaningful insights from raw data. It encompasses the end-to-end journey, from problem identification and data collection to model deployment and ongoing monitoring.
Why do we need a data science life cycle?
The data science lifecycle aims to provide a structured framework for tackling data-related challenges, ensuring that the insights generated align with business objectives and contribute to informed decision-making.
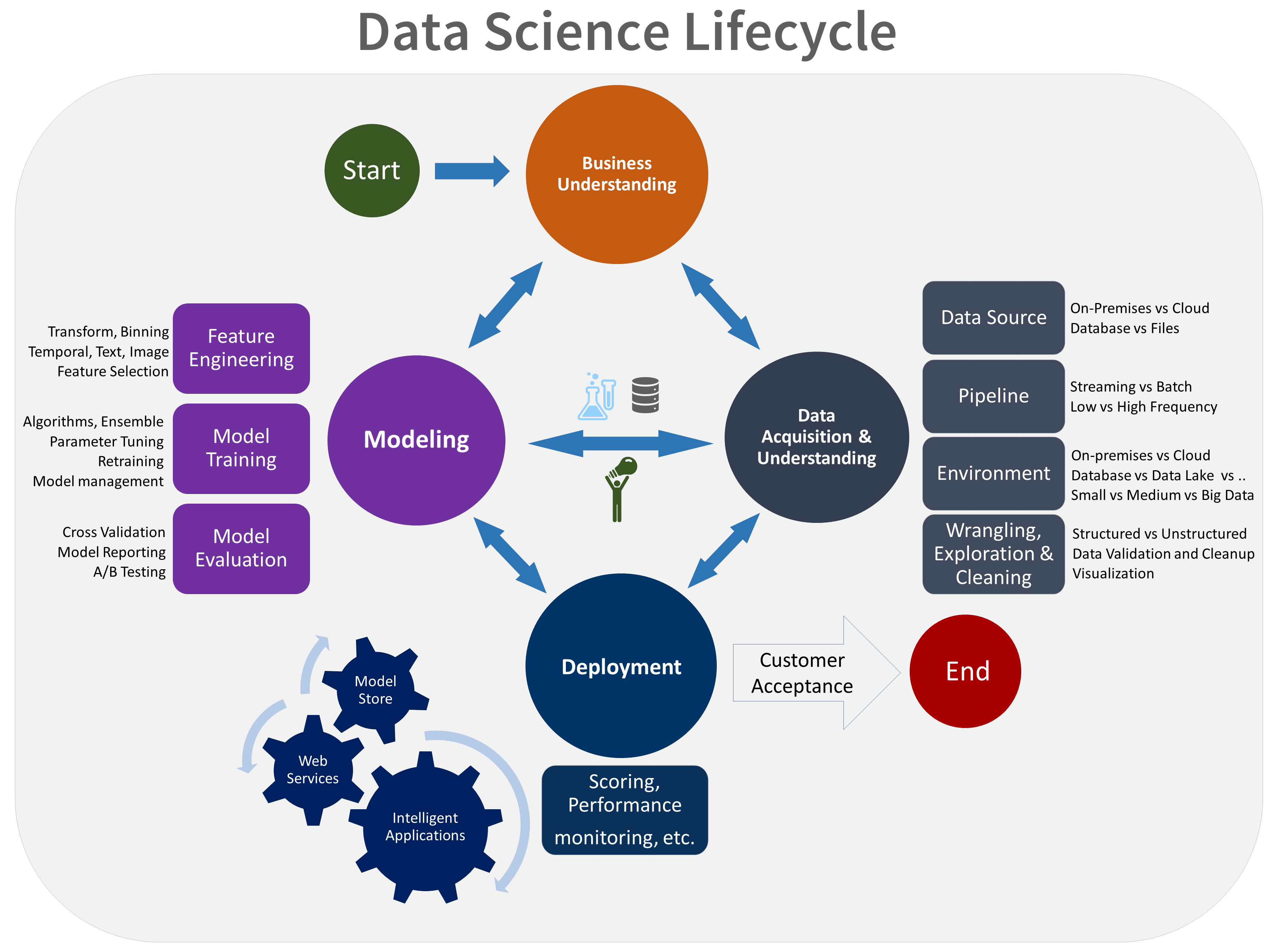
Steps in the Data Science Lifecycle
Here are the key stages of the data science lifecycle and the significance of each step,
Step 1 - Problem-Definition and Planning
Every successful data science project begins with a clear understanding of the problem at hand.
During this phase, teams collaborate with stakeholders to define objectives, scope, and key performance indicators (KPIs). Establishing a solid foundation ensures the subsequent stages align with organizational goals and expectations.
Step 2 - Data Collection
Data is the lifeblood of any data science endeavour. Collecting relevant and high-quality data is crucial for obtaining accurate and meaningful results.
This phase involves sourcing data from various channels, such as databases, APIs, and external datasets. The collected data may include structured, unstructured, or semi-structured information.
Step 3 - Data Cleaning and Preprocessing
Raw data is often messy and may contain errors, missing values, or inconsistencies. Data cleaning and preprocessing involve transforming the raw data into a clean and usable format.
Techniques such as imputation, normalization, and outlier detection are applied to enhance data quality and prepare it for analysis.
Step 4 - Exploratory Data Analysis (EDA)
EDA is a critical step where data scientists explore and visualize the dataset to gain insights into its characteristics.
Descriptive statistics, data visualization tools, and correlation analyses are used to uncover patterns, trends, and potential relationships within the data. EDA helps in formulating hypotheses and guiding further analysis.
{% module_block module "widget_a5be6386-3597-4417-8753-0896a040daa9" %}{% module_attribute "child_css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "definition_id" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "field_types" is_json="true" %}{% raw %}{"link":"text","text":"text"}{% endraw %}{% end_module_attribute %}{% module_attribute "label" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "link" is_json="true" %}{% raw %}"https://www.odinschool.com/blog/a-complete-guide-on-exploratory-data-analysis"{% endraw %}{% end_module_attribute %}{% module_attribute "module_id" is_json="true" %}{% raw %}135590387735{% endraw %}{% end_module_attribute %}{% module_attribute "path" is_json="true" %}{% raw %}"/OdinSchool_V3/modules/Blog/blog - source links"{% endraw %}{% end_module_attribute %}{% module_attribute "schema_version" is_json="true" %}{% raw %}2{% endraw %}{% end_module_attribute %}{% module_attribute "smart_objects" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "smart_type" is_json="true" %}{% raw %}"NOT_SMART"{% endraw %}{% end_module_attribute %}{% module_attribute "tag" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "text" is_json="true" %}{% raw %}"A Complete Guide on Exploratory Data Analysis"{% endraw %}{% end_module_attribute %}{% module_attribute "type" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "wrap_field_tag" is_json="true" %}{% raw %}"div"{% endraw %}{% end_module_attribute %}{% end_module_block %}Step 5 - Feature Engineering
Feature engineering involves selecting, transforming, or creating new features from the existing dataset to enhance model performance.
This step aims to highlight relevant information and reduce the dimensionality of the data. Domain knowledge plays a crucial role in identifying features that contribute significantly to the problem at hand.
{% module_block module "widget_943b6d0f-9977-474c-a606-e0a2834ee5b4" %}{% module_attribute "child_css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "definition_id" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "field_types" is_json="true" %}{% raw %}{"link":"text","text":"text"}{% endraw %}{% end_module_attribute %}{% module_attribute "label" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "link" is_json="true" %}{% raw %}"https://www.odinschool.com/blog/data-science/10-machine-learning-models-to-know-for-beginners"{% endraw %}{% end_module_attribute %}{% module_attribute "module_id" is_json="true" %}{% raw %}135590387735{% endraw %}{% end_module_attribute %}{% module_attribute "path" is_json="true" %}{% raw %}"/OdinSchool_V3/modules/Blog/blog - source links"{% endraw %}{% end_module_attribute %}{% module_attribute "schema_version" is_json="true" %}{% raw %}2{% endraw %}{% end_module_attribute %}{% module_attribute "smart_objects" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "smart_type" is_json="true" %}{% raw %}"NOT_SMART"{% endraw %}{% end_module_attribute %}{% module_attribute "tag" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "text" is_json="true" %}{% raw %}"10 Essential Machine Learning Models You Should Know"{% endraw %}{% end_module_attribute %}{% module_attribute "type" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "wrap_field_tag" is_json="true" %}{% raw %}"div"{% endraw %}{% end_module_attribute %}{% end_module_block %}Step 6 - Modelling
Data scientists apply various machine learning algorithms to build predictive or descriptive models in the modelling phase.
The choice of the algorithm depends on the nature of the problem (classification, regression, clustering, etc.) and the characteristics of the data. Model training, validation, and tuning are iterative processes aimed at achieving optimal performance.
{% module_block module "widget_585b89b1-b920-42c0-a588-5f5c8f11ef25" %}{% module_attribute "child_css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "definition_id" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "field_types" is_json="true" %}{% raw %}{"link":"text","text":"text"}{% endraw %}{% end_module_attribute %}{% module_attribute "label" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "link" is_json="true" %}{% raw %}"https://www.odinschool.com/blog/data-science/linear-regression-with-python-scikit-learn"{% endraw %}{% end_module_attribute %}{% module_attribute "module_id" is_json="true" %}{% raw %}135590387735{% endraw %}{% end_module_attribute %}{% module_attribute "path" is_json="true" %}{% raw %}"/OdinSchool_V3/modules/Blog/blog - source links"{% endraw %}{% end_module_attribute %}{% module_attribute "schema_version" is_json="true" %}{% raw %}2{% endraw %}{% end_module_attribute %}{% module_attribute "smart_objects" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "smart_type" is_json="true" %}{% raw %}"NOT_SMART"{% endraw %}{% end_module_attribute %}{% module_attribute "tag" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "text" is_json="true" %}{% raw %}"Linear Regression With Python scikit Learn"{% endraw %}{% end_module_attribute %}{% module_attribute "type" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "wrap_field_tag" is_json="true" %}{% raw %}"div"{% endraw %}{% end_module_attribute %}{% end_module_block %}Step 7 - Evaluation
Once models are trained, they must be evaluated to assess their performance. Metrics such as accuracy, precision, recall, and F1 score are used to quantify the model's effectiveness.
The evaluation phase helps identify the best-performing model and ensures that it generalizes well to new, unseen data.
Step 8 - Deployment
A successful model is useless if it remains confined to a development environment. Deployment involves integrating the model into production systems, making it accessible for end-users or automated processes.
Implementation considerations such as scalability, efficiency, and real-time processing are crucial at this stage.
Step 9 - Monitoring and Maintenance
The data science lifecycle doesn't end with deployment; continuous monitoring is essential to ensure the model performs well over time.
Monitoring involves tracking model accuracy, detecting drift in data patterns, and updating the model as needed. Maintenance activities may include retraining the model with new data or adapting to evolving business requirements.
So,
The data science lifecycle is a dynamic and iterative process that transforms raw data into actionable insights. Each stage is crucial in the journey from problem definition to model deployment and beyond.
By following this systematic approach, organizations can harness the power of data science to make informed decisions, drive innovation, and gain a competitive edge in today's data-driven landscape.

Challenges in the Data Science Life Cycle
Understanding and navigating these challenges at each stage of the data science lifecycle is integral to ensuring the reliability, accuracy, and practicality of data-driven solutions.
Challenge 1 - Problem Definition and Planning
-
Ambiguous Objectives: Defining clear and measurable objectives can be challenging, especially when stakeholders have diverse expectations. Ensuring alignment between business goals and analytical objectives is crucial.
-
Limited Domain Knowledge: Data scientists may face challenges without sufficient domain knowledge. Collaborating closely with subject matter experts becomes essential to bridge this gap.
Challenge 2 - Data Collection
-
Data Accessibility: Accessing relevant and comprehensive data can be challenging, especially when dealing with proprietary or sensitive information. Overcoming data silos and ensuring data availability is a common hurdle.
-
Data Quality: Incomplete, inaccurate, or inconsistent data can significantly impact the quality of analyses. Data cleaning and preprocessing become critical to address these issues.
Challenge 3 - Data Cleaning and Preprocessing
-
Missing Data: Dealing with missing values requires careful consideration. Imputation methods or deciding when and how to handle missing data can influence the quality of the final model.
-
Outlier Detection: Identifying and handling outliers is crucial. Decisions on whether to remove, transform, or keep outliers can impact the model's robustness.
Challenge 4 - Exploratory Data Analysis (EDA)
-
Overfitting Assumptions: Drawing conclusions based on initial visualizations may lead to overfitting assumptions. It's essential to validate findings through statistical tests and hypothesis testing.
-
Interpreting Patterns: Identifying meaningful patterns in data visualizations can be subjective. Ensuring that patterns are not coincidental and hold statistical significance is a challenge.
Challenge 5 - Feature Engineering
-
Selection Dilemma: Choosing the right features from a pool of potential candidates is challenging. Feature selection methods must balance relevance, redundancy, and computational efficiency.
-
Creating Informative Features: Crafting new features contributing to the model's predictive power requires creativity and a deep understanding of the problem domain.
Challenge 6 - Modelling
-
Algorithm Selection: Choosing the most suitable algorithm for a specific problem is not always straightforward. Different algorithms have different strengths and weaknesses, and the optimal choice depends on the nature of the data.
-
Hyperparameter Tuning: Configuring model hyperparameters for optimal performance can be time-consuming. The search for the right combination requires a balance between computation time and model accuracy.
Challenge 7 - Evaluation
-
Metric Selection: The choice of evaluation metrics depends on the nature of the problem (classification, regression, etc.). Selecting appropriate metrics that align with business objectives is crucial.
-
Overfitting Evaluation Data: Evaluating models on the same data used for training can lead to overfitting. Techniques like cross-validation help mitigate this challenge.
Challenge 8 - Deployment
-
Scalability: Deploying models at scale may pose challenges, particularly when dealing with large datasets or real-time processing requirements. Ensuring that the infrastructure can handle increased loads is essential.
-
Integration with Existing Systems: Integrating the deployed model with existing systems, databases, or applications can be complex. Compatibility issues may arise, requiring careful planning and collaboration with IT teams.
Challenge 9 - Monitoring and Maintenance
-
Concept Drift: Changes in the underlying data distribution over time can impact model performance. Implementing effective monitoring to detect and address concept drift is crucial for model longevity.
-
Continuous Improvement: Updating models with new data or adapting to changing business requirements requires ongoing effort. Establishing a process for continuous improvement and updates is essential for the sustained success of the deployed models.
So,
Addressing these hurdles requires combining technical expertise, collaboration, and a nuanced understanding of the specific context in which data science is applied. Hence, it is essential to join a data science course that can provide a structured and industry-vetted curriculum.
Data Science - Continuous Learning
The field of data science evolves rapidly with the introduction of new tools, algorithms, and methodologies. Continuous learning ensures that professionals stay current with the latest advancements.
Here are some key pointers to explain why continuous learning is essential for all data science enthusiasts.
-
Data science is applied across various industries, each with its unique challenges. Continuous learning allows individuals to acquire specialized knowledge relevant to their domains of interest.
-
Employers value professionals who demonstrate a commitment to learning. Continuous skill development enhances career prospects and increases adaptability in a competitive job market.
-
Learning new techniques and approaches fosters innovative problem-solving. Keeping skills sharp allows data scientists to tackle complex challenges creatively and efficiently.
In conclusion, a commitment to continuous learning is essential for individuals pursuing a career in data science.
By leveraging the wealth of resources available online or joining an online data science course, professionals can ensure that their skills remain relevant and adaptable to the ever-changing data science landscape.
{% module_block module "widget_496576a0-66f1-46e5-bb0d-1ce949b8944b" %}{% module_attribute "child_css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "definition_id" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "field_types" is_json="true" %}{% raw %}{"link":"text","text":"text"}{% endraw %}{% end_module_attribute %}{% module_attribute "label" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "link" is_json="true" %}{% raw %}"https://www.odinschool.com/blog/data-science-pay-after-placement-pros-and-cons"{% endraw %}{% end_module_attribute %}{% module_attribute "module_id" is_json="true" %}{% raw %}135590387735{% endraw %}{% end_module_attribute %}{% module_attribute "path" is_json="true" %}{% raw %}"/OdinSchool_V3/modules/Blog/blog - source links"{% endraw %}{% end_module_attribute %}{% module_attribute "schema_version" is_json="true" %}{% raw %}2{% endraw %}{% end_module_attribute %}{% module_attribute "smart_objects" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "smart_type" is_json="true" %}{% raw %}"NOT_SMART"{% endraw %}{% end_module_attribute %}{% module_attribute "tag" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "text" is_json="true" %}{% raw %}"Data Science Pay-After-Placement: Pros and Cons"{% endraw %}{% end_module_attribute %}{% module_attribute "type" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "wrap_field_tag" is_json="true" %}{% raw %}"div"{% endraw %}{% end_module_attribute %}{% end_module_block %}Frequently Asked Questions

What is the role of the data lifecycle?
The data lifecycle refers to the stages that data goes through, from its creation or acquisition to its eventual deletion or archival. It encompasses various processes and activities that ensure the proper management, utilization, and protection of data throughout its existence.
What are the three main goals of the data lifecycle?
To ensure a seamless flow of information throughout its lifecycle, the three main goals of the data lifecycle are often summarized as the three Cs: Capture, Consume, and Control.
Can I become a data engineer?
Absolutely! Many people successfully transition into data science from various educational backgrounds. Here is an awesome success story of who was a tutor who transformed into a data engineer in 6 months after a 5-Year career gap!