Top 55 Python Interview Questions and Answers

Rising demand for python in end-end applications is due to,
-
Increase in adoption of data analytics by enterprises
-
Growing dependency on Python over other programming languages
-
Increase in demand of python for real time Internet of Things
Python Interview Questions
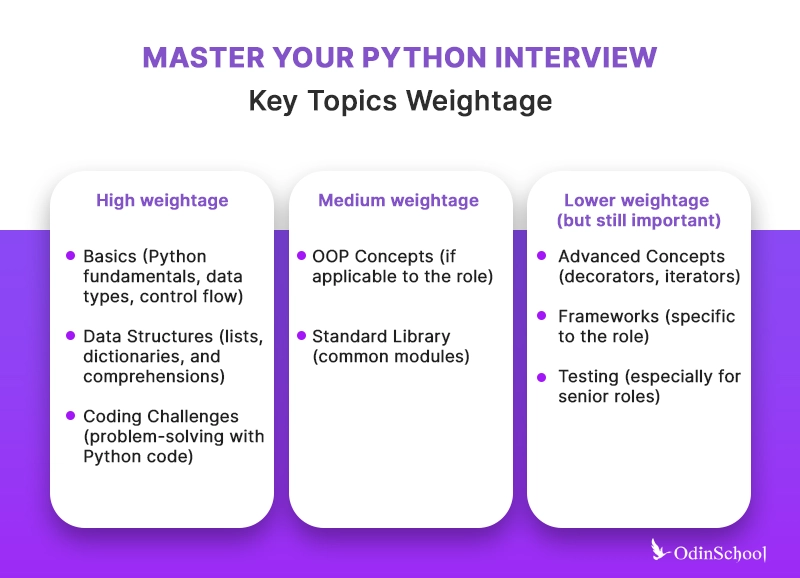
Following are the topics on which Python interviews are conducted, so here are some Python interview questions with answers that might help you know how prepared you are.
Python Fundamentals
Questions may include topics like data types, variables, basic operators, and understanding Python's syntax and semantics.
Q1: Demonstrate the difference between a shallow copy and a deep copy when working with a list of lists in Python. Provide code examples that illustrate potential issues with each method.
# Create a list containing other lists
original = [[1, 2, 3], [4, 5, 6]]
# Shallow copy
shallow_copied = copy.copy(original)
shallow_copied[0][0] = 0
# Deep copy
deep_copied = copy.deepcopy(original)
deep_copied[1][1] = 0
print("Original:", original) # Original: [[0, 2, 3], [4, 5, 6]], showing that shallow copy affected the original
print("Shallow Copied:", shallow_copied) # Shallow Copied: [[0, 2, 3], [4, 5, 6]]
print("Deep Copied:", deep_copied) # Deep Copied: [[1, 2, 3], [4, 0, 6]]
This example demonstrates how changes to a list within the list affect the original list when a shallow copy is used, due to both sharing references to the same inner lists. A deep copy, on the other hand, creates new inner lists, so changes do not affect the original.
Q2: How can cyclic dependencies in imports be problematic in Python? Provide an example and explain a strategy to resolve such issues.
Cyclic dependencies occur when two more modules depend on each other either directly or indirectly, causing an infinite loop and potential ImportError. Here's a simplified example:
module_a.py:
from module_b import B
class A:
def __init__(self):
self.b = B()
module_b.py:
from module_a import A
class B:
def __init__(self):
self.a = A()
This structure will lead to an ImportError. A solution is to refactor the import statements:
# In module_b.py
class B:
def __init__(self):
from module_a import A
self.a = A()
By moving the import statement inside the method or function, it defers the loading of the dependent module until it's needed, breaking the cyclic dependency.
Q3: Write a Python context manager that logs entry and exit from a block of code, demonstrating resource management.
from contextlib import contextmanager
import time
@contextmanager
def timed_block(label):
start_time = time.time()
try:
yield
finally:
end_time = time.time()
print(f"{label} took {end_time - start_time:.3f} seconds")
# Usage:
with timed_block("Processing"):
sum = 0
for i in range(1000000):
sum += i
Q4: Implement a memoization decorator that caches the results of a function based on its arguments.
def memoize(f):
memo = {}
def helper(x):
if x not in memo:
memo[x] = f(x)
return memo[x]
return helper
@memoize
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
Q5: Explain a common pitfall in Python's asyncio library and how to avoid it. Provide a code example.
One common pitfall is calling an asynchronous function without await, which means the function is never actually executed. This often happens due to a misunderstanding of how coroutines work in Python.
import asyncio
async def do_work():
print("Work Started")
await asyncio.sleep(1) # Simulate I/O task
print("Work Finished")
async def main():
# Incorrect call, does nothing
do_work()
# Correct call
await do_work()
asyncio.run(main())
Data Structures
Understanding and using Python's built-in data structures like lists, dictionaries, sets, and tuples. Questions might involve operations on these data structures, such as adding or removing elements, iterating, or sorting.
Q6: Implement a function to reverse a singly linked list in Python without using any additional data structures. Describe the algorithm and provide the code.
A: To reverse a singly linked list, you need to change the next pointers of each node so that they point to the previous node. This can be achieved using three pointers: previous, current, and next.
class Node:
def __init__(self, data):
self.data = data
self.next = None
def reverse_linked_list(head):
previous = None
current = head
while current:
next = current.next
current.next = previous
previous = current
current = next
return previous
# Example Usage
head = Node(1)
head.next = Node(2)
head.next.next = Node(3)
reversed_list = reverse_linked_list(head)
current = reversed_list
while current:
print(current.data, end=" -> ")
current = current.next
Q7: Using two stacks, implement a queue that supports all queue operations (enqueue, dequeue) in amortized O(1) time. Explain the mechanism behind your solution and provide the implementation in Python.
The key idea is to use two stacks, stack_in for enqueue operations and stack_out for dequeue operations. When stack_out is empty and a dequeue is required, the contents of stack_in are transferred to stack_out, reversing the order and making the oldest element available.
class QueueWithStacks:
def __init__(self):
self.stack_in = []
self.stack_out = []
def enqueue(self, x):
self.stack_in.append(x)
def dequeue(self):
if not self.stack_out:
while self.stack_in:
self.stack_out.append(self.stack_in.pop())
return self.stack_out.pop()
# Example Usage
q = QueueWithStacks()
q.enqueue(1)
q.enqueue(2)
q.enqueue(3)
print(q.dequeue()) # Output: 1
print(q.dequeue()) # Output: 2
Q8: Write a function to check whether a binary tree is a binary search tree (BST).
A BST is a tree in which each node contains a key greater than all the keys in the node's left subtree and less than those in its right subtree. To check this, perform an in-order traversal and ensure the resulting list of keys is sorted in ascending order.
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
def is_bst(node, lower=float('-inf'), upper=float('inf')):
if not node:
return True
val = node.val
if val <= lower or val >= upper:
return False
if not is_bst(node.right, val, upper):
return False
if not is_bst(node.left, lower, val):
return False
return True
# Example Usage
root = TreeNode(2)
root.left = TreeNode(1)
root.right = TreeNode(3)
print(is_bst(root)) # Output: True
Q9: Write a function to detect a cycle in a linked list. If a cycle exists, return the starting node of the cycle.
Floyd's Cycle Detection Algorithm (also known as the Tortoise and the Hare algorithm) is an efficient method to detect cycles. It uses two pointers moving at different speeds. If there is a cycle, the fast pointer (hare) will eventually meet the slow pointer (tortoise).
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
def detectCycle(head):
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
if slow == fast:
while head != slow:
head = head.next
slow = slow.next
return head
return None
# Example Usage
node1 = ListNode(3)
node2 = ListNode(2)
node3 = ListNode(0)
node4 = ListNode(-4)
node1.next = node2
node2.next = node3
node3.next = node4
node4.next = node2 # Creates a cycle that starts at node2
print(detectCycle(node1).val) # Output: 2
Q10: Implement an LRU (Least Recently Used) cache that supports the get and put operations.
An LRU cache can be implemented using a combination of a doubly linked list and a hash map. The doubly linked list maintains items in order of usage, with the least recently used items near the tail and the most recently used near the head. The hash map stores keys and pointers to the corresponding nodes in the doubly linked list to ensure O(1) access time.
class LRUCache:
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.prev = None
self.next = None
def __init__(self, capacity):
self.capacity = capacity
self.dict = {}
self.head = self.Node(0, 0)
self.tail = self.Node(0, 0)
self.head.next = self.tail
self.tail.prev = self.head
def get(self, key):
if key in self.dict:
n = self.dict[key]
self._remove(n)
self._add(n)
return n.value
return -1
def put(self, key, value):
if key in self.dict:
self._remove(self.dict[key])
n = self.Node(key, value)
self._add(n)
self.dict[key] = n
if len(self.dict) > self.capacity:
n = self.head.next
self._remove(n)
del self.dict[n.key]
def _remove(self, node):
p, n = node.prev, node.next
p.next, n.prev = n, p
def _add(self, node):
p = self.tail.prev
p.next = node
self.tail.prev = node
node.prev = p
node.next = self.tail
# Example Usage
cache = LRUCache(2)
cache.put(1, 1)
cache.put(2, 2)
print(cache.get(1)) # returns 1
cache.put(3, 3) # evicts key 2
print(cache.get(2)) # returns -1 (not found)
Control Structures
Knowledge of conditional statements (if, elif, else), loops (for, while), and comprehension techniques is mandatory.
Q11: Write a function to find the position of a given value in a sorted 2D matrix where each row and each column is sorted in ascending order. Assume no duplicates. Provide both the position and the Python code.
This problem can be approached by using a staircase search algorithm, starting from the top-right corner and moving based on comparisons.
def search_in_sorted_matrix(matrix, target):
if not matrix or not matrix[0]:
return (-1, -1)
row, col = 0, len(matrix[0]) - 1
while row < len(matrix) and col >= 0:
if matrix[row][col] == target:
return (row, col)
elif matrix[row][col] > target:
col -= 1
else:
row += 1
return (-1, -1)
# Example matrix and target
matrix = [
[1, 4, 7, 11],
[2, 5, 8, 12],
[3, 6, 9, 16]
]
target = 8
print(search_in_sorted_matrix(matrix, target)) # Output: (1, 2)
Q12: Create a Python function that finds all unique triplets in an array that sum up to zero. Provide a solution that avoids using excessive brute force.
This can be solved efficiently using a combination of sorting and the two-pointer technique.
def three_sum(nums):
nums.sort()
result = []
for i in range(len(nums) - 2):
if i > 0 and nums[i] == nums[i - 1]:
continue
left, right = i + 1, len(nums) - 1
while left < right:
total = nums[i] + nums[left] + nums[right]
if total < 0:
left += 1
elif total > 0:
right -= 1
else:
result.append([nums[i], nums[left], nums[right]])
while left < right and nums[left] == nums[left + 1]:
left += 1
while left < right and nums[right] == nums[right - 1]:
right -= 1
left += 1
right -= 1
return result
# Example usage
nums = [-1, 0, 1, 2, -1, -4]
print(three_sum(nums)) # Output: [[-1, -1, 2], [-1, 0, 1]]
Q13: Implement a Python function that returns the first recurring character in a string using a single pass and without additional data structures.
This can be challenging due to the constraints, but can be approached by using bitwise operations to check seen characters, assuming the string only contains letters a-z.
def first_recurring_character(s):
seen = 0
for char in s:Related Articles