Python Tutorial (2024): Introduction to Data Science with Python

Let’s face it: if we were to designate a programming language as the heart-throb amongst all programming languages, Python would take the spotlight.
Python is one of the world's most popular and fastest-growing programming languages. While data science is a vast and multidisciplinary field, Python programming is the go-to choice for most data science professionals. Thanks to its versatility, using Python for data science and analytics is a smooth experience.
That is why this Python tutorial will walk you through the following:
1. The Role of Python in Data Science
2. Various Python Libraries for Data Science
3. Python installation on Windows, macOS, Linus, and virtual environments
4. Some practical examples
Let's embark on this exciting journey into data science with this Python tutorial as your companion!

What is Data Science?
Data science aims to uncover hidden patterns, trends, and correlations within vast datasets, transforming raw information into actionable intelligence. It encompasses various techniques, including data exploration, statistical modelling, machine learning, and advanced analytics.
What sets data science apart is its amalgamation of diverse disciplines. It merges statistical reasoning to interpret patterns, mathematical modelling for predictive analysis, and computer science for efficient data processing and algorithm development. Moreover, domain expertise is crucial as it ensures that data scientists understand the context and nuances specific to the industry or field they are working in.
This data science roadmap will help you know everything, like data science roles along with salaries, etc.
-1.webp)
Why is Data Science important?
Data science is pivotal in today's data-driven world, offering solutions to complex problems and contributing to evidence-based decision-making. Its significance extends to:
-
Problem Solving: Data science provides methodologies to tackle intricate problems by extracting meaningful patterns from vast datasets, enabling organizations to make informed decisions.
-
Predictive Analytics: Through statistical modelling and machine learning algorithms, data science enables the prediction of future trends and outcomes, aiding businesses in proactive planning.
-
Optimizing Operations: Industries leverage data science to enhance operational efficiency, streamline processes, and identify areas for improvement.
-
Informed Decision-Making: Decision-makers rely on data science to access relevant insights, reducing uncertainty and increasing the probability of making successful choices.
To underscore the real-world impact of data science, consider the following examples:
-
Healthcare: Predictive analytics helps forecast disease outbreaks, optimize patient treatment plans, and improve healthcare delivery.
-
Finance: Financial institutions use data science for risk assessment, fraud detection, and personalized financial recommendations.
-
E-commerce: Online retailers employ recommendation systems based on user behaviour analysis, enhancing customer experience and boosting sales.
-
Manufacturing: Data science is utilized for predictive maintenance, reducing downtime and optimizing production processes in manufacturing.
These and many more examples, especially in sports, illustrate how data science transforms industries, making it an indispensable tool for innovation and progress.
{% module_block module "widget_e5b6d39b-65f1-4c6e-b903-667a49884e34" %}{% module_attribute "child_css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "definition_id" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "field_types" is_json="true" %}{% raw %}{"link":"text","text":"text"}{% endraw %}{% end_module_attribute %}{% module_attribute "label" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "link" is_json="true" %}{% raw %}"https://www.odinschool.com/blog/unleashing-the-power-of-data-science-in-sports-case-studies"{% endraw %}{% end_module_attribute %}{% module_attribute "module_id" is_json="true" %}{% raw %}135590387735{% endraw %}{% end_module_attribute %}{% module_attribute "path" is_json="true" %}{% raw %}"/OdinSchool_V3/modules/Blog/blog - source links"{% endraw %}{% end_module_attribute %}{% module_attribute "schema_version" is_json="true" %}{% raw %}2{% endraw %}{% end_module_attribute %}{% module_attribute "smart_objects" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "smart_type" is_json="true" %}{% raw %}"NOT_SMART"{% endraw %}{% end_module_attribute %}{% module_attribute "tag" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "text" is_json="true" %}{% raw %}"Read More - Power of Data Science in Sports - Case Studies"{% endraw %}{% end_module_attribute %}{% module_attribute "type" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "wrap_field_tag" is_json="true" %}{% raw %}"div"{% endraw %}{% end_module_attribute %}{% end_module_block %}What is Python? How is Python used for Data Science?
Python is an object-oriented, high-level programming language with a vast community; Java is easy to learn and remember, making it suitable for beginners.
 Python's popularity in the data science community can be attributed to several factors:
Python's popularity in the data science community can be attributed to several factors:
-
Simplicity and Readability: Python's syntax is clean, readable, and easy to learn. This makes it an ideal choice for data scientists, including those who may not have a deep background in programming.
-
Rich Ecosystem: Python boasts a rich ecosystem of libraries and frameworks specifically designed for data science and machine learning. These libraries, such as NumPy, pandas, Matplotlib, and sci-kit-learn, simplify data manipulation, analysis, and modelling tasks.
-
Community Support: Python has a vibrant and welcoming community. Data scientists can find many resources, tutorials, and forums to help them along their journey.
-
Cross-Platform Compatibility: Python is platform-agnostic, making working on various operating systems easy.
-
Integration: Python seamlessly integrates with other languages like R and SQL, allowing data scientists to leverage different tools as needed.
What is the advantage of using Python programming in data science?
Python has emerged as the predominant programming language in data science, and several factors contribute to its prominence.
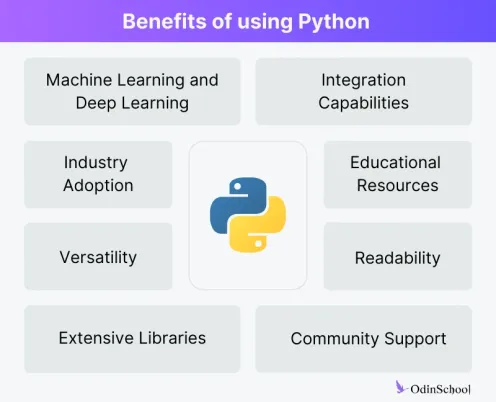
-
Readability: Python's syntax is clean, readable, and straightforward, making it an ideal language for beginners and experts. Its emphasis on code readability promotes collaboration and ease of understanding, crucial aspects when dealing with complex data science projects.
-
Extensive Libraries: Python boasts a rich ecosystem of libraries and frameworks specifically designed for data science. Notable among them are NumPy and Pandas for data manipulation, Matplotlib and Seaborn for visualization, and Scikit-Learn for machine learning. The availability of these robust libraries significantly accelerates the development and implementation of data science solutions.
-
Versatility: Python is a versatile language that integrates seamlessly with other technologies and tools. This interoperability allows data scientists to incorporate data analysis into various project stages, from data collection to model deployment.
-
Machine Learning and Deep Learning: Python is the language of choice for machine learning and deep learning applications. Frameworks such as TensorFlow and PyTorch, widely used for building and training neural networks, have Python interfaces, fostering a unified environment for data scientists.
-
Community Support: Python boasts a vibrant and active community of developers and data scientists. This community support is invaluable for troubleshooting issues, sharing best practices, and staying updated with the latest advancements in the field. The collaborative nature of the Python community enhances the learning experience and accelerates problem-solving.
-
Integration Capabilities: Python seamlessly integrates with C and C++, allowing developers to leverage existing code and tools. It also integrates well with databases, making it a preferred choice for database programming.
-
Educational Resources: Python's popularity has led to abundant educational resources, tutorials, and documentation. This wealth of learning materials facilitates the onboarding of new practitioners into the field of data science, contributing to its continuous growth.
-
Industry Adoption: Many prominent tech companies and organizations have adopted Python for their data science and machine learning initiatives. This industry-wide acceptance further solidifies Python's position as the primary language for data science.
In essence, Python's readability, extensive libraries, versatility, and the strong support of its community make it the go-to language for data scientists. Its role extends beyond just being a programming language; it is a powerful tool that empowers data scientists to address the challenges of the ever-evolving data landscape efficiently.

Which Python library is used in Data Science?
Several.
Python has numerous libraries; different libraries specialize in various aspects of the data science workflow. Each library has its strengths and is designed to address specific tasks efficiently.
The following are some of the popular Python libraries for Data Science.
NumPy and Pandas
Role: NumPy is a fundamental library for performing numerical operations in Python. It supports large, multi-dimensional arrays, matrices, and mathematical functions for efficiently operating on these arrays.
Key Features
-
Efficient array operations for numerical computing.
-
Mathematical functions for array manipulation.
-
Broadcasting capabilities for performing operations on arrays of different shapes.
Pandas
Role: Panda is a versatile library designed for data manipulation and analysis. It introduces two primary data structures, Series and DataFrame, that enable efficient handling of labelled and structured data.
Key Features
- DataFrame for tabular data manipulation.
- Powerful data indexing and selection capabilities.
- Data cleaning and preprocessing functions.
- Integration with other data analysis libraries.
Matplotlib and Seaborn
Role: Matplotlib is a comprehensive 2D plotting library for creating static, animated, and interactive visualizations in Python. It provides various plotting options for showcasing data patterns and trends.
Key Features
- Line plots, scatter plots, bar plots, and more.
- Customization options for plot appearance.
- Support for creating complex visualizations.
Role: Seaborn is built on top of Matplotlib and is specifically designed for statistical data visualization. It simplifies the process of creating informative and attractive statistical graphics.
Key Features
- Simplified syntax for complex visualizations.
- Specialized plots for statistical analysis.
- Integration with Pandas DataFrames.
Scikit-Learn
Role: Scikit-Learn is a machine learning library providing simple and efficient data analysis and modelling tools. It includes various classification, regression, clustering, and model selection algorithms.
Key Features- Consistent API for various machine learning tasks.
- Tools for data preprocessing and feature engineering.
- Model evaluation and selection functions.
TensorFlow and PyTorch
Role: TensorFlow is an open-source machine learning framework developed by Google. It is widely used to build and train deep learning models, including neural networks.
Key Features:
- Flexible architecture for building complex neural networks.
- Support for both traditional machine learning and deep learning.
- Extensive community and ecosystem.
PyTorch
Role: PyTorch is another popular deep-learning library that offers dynamic computation graphs, making it intuitive for researchers and developers. It is known for its ease of use and flexibility.
Key Features
- Dynamic computational graph for more flexibility.
- Strong support for research-oriented tasks.
- Growing community and adoption.
These libraries collectively form the backbone of data science in Python, providing essential tools for data manipulation, visualization, machine learning, and deep learning. Depending on a project's specific requirements, data scientists leverage these libraries to perform diverse tasks throughout the data science pipeline.
Setting Up Your Python Environment for Python Programming
Python Installation
Download Python: Visit the official Python website (https://www.python.org/downloads/) and choose the latest version suitable for your operating system (Windows, macOS, or Linux).
Installation Steps (Windows):
- Run the downloaded installer.
- Check the box that says "Add Python X.X to PATH" during installation.
- Click "Install Now" to begin the installation.
- Follow the instructions in the terminal after downloading.
- Ensure that Python is added to your system's PATH.
- Open a terminal or command prompt.
- Type python --version or python -V to confirm the installed Python version.
Using Virtual Environments
1. Install Virtualenv (if not installed):
- Open a terminal or command prompt.
- Run pip install virtualenv.
2. Create a Virtual Environment:
- Navigate to your project directory in the terminal.
- Run python -m venv venv to create a virtual environment named "venv" (you can choose a different name).
3. Activate the Virtual Environment:
- Windows: venv\Scripts\activate
- macOS/Linux: source venv/bin/activate
Note: Your command prompt or terminal should now show the virtual environment's name.
4. Deactivate the Virtual Environment:
- Run deactivate in the terminal.
Package Management with Pip
1. Install Packages
- After activating the virtual environment, use pip install package_name to install Python packages. For example, pip install numpy pandas matplotlib
2. Create requirements.txt
- Save a list of installed packages for reproducibility.
- Run pip freeze > requirements.txt to generate the file.
3. Install Packages from requirements.txt
- Use pip install -r requirements.txt to install all packages listed in the file.
Why Use Virtual Environments
- Isolation: Ensures project-specific dependencies don't interfere with system-wide Python packages.
- Reproducibility: Allows you to recreate the exact environment with specified package versions.
Why Use requirements.txt
- Reproducibility: Captures all dependencies and their versions for others to replicate the environment.
- Consistency: Ensures that everyone working on the project uses the same package versions, minimizing compatibility issues.
Practical Examples and Projects
Exploratory Data Analysis (EDA):
1. Import Libraries:- import pandas as pd
- import matplotlib.pyplot as plt
2. Load Dataset:
- # Assuming 'df' is your DataFrame
- df = pd.read_csv('your_dataset.csv')
3. Understand the Dataset:
- View first few rows: df.head()
- Summary statistics: df.describe()
- Data types and missing values: df.info()
4. Data Visualization with Matplotlib:
# Example: Histogram of a numeric columnplt.hist(df['numeric_column'], bins=20)
plt.title('Distribution of Numeric Column')
plt.xlabel('Values')
plt.ylabel('Frequency')
plt.show()
5. Correlation Analysis:
# Example: Correlation matrix
correlation_matrix = df.corr()
plt.imshow(correlation_matrix, cmap='coolwarm', interpolation='none')
plt.colorbar()
plt.xticks(range(len(correlation_matrix)), correlation_matrix.columns, rotation=90)
plt.yticks(range(len(correlation_matrix)), correlation_matrix.columns)
plt.title('Correlation Matrix')
plt.show()
Importance of Understanding the Dataset:
- Identifying data types, missing values, and outliers.
- Uncovering patterns and trends in the data.
- Informing decisions on data preprocessing and modelling.
Machine Learning Example:
1. Import Libraries:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
2. Load and Preprocess Data:
# Assuming 'df' has features and target column 'target'
X = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
3. Train Logistic Regression Model:
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
4. Evaluate the Model:
y_pred = model.predict(X_test_scaled)
print('Accuracy:', accuracy_score(y_test, y_pred))
print('Classification Report:\n', classification_report(y_test, y_pred))
print('Confusion Matrix:\n', confusion_matrix(y_test, y_pred))
Deep Learning Project (Optional):
Note: This is a simplified example. Deep learning projects often require more complex architectures and tuning.
1. Import Libraries:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
2. Load and Preprocess Data:
# Assuming 'df' has features and target column 'target'
X = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
3. Build a Simple Neural Network:
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=X_train_scaled.shape[1]))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
4. Train the Neural Network:
model.fit(X_train_scaled, y_train, epochs=10, batch_size=32, validation_data=(X_test_scaled, y_test))
loss, accuracy = model.evaluate(X_test_scaled, y_test)
print(f'Loss: {loss}, Accuracy: {accuracy}')
Note:
- The examples provided are illustrative. Real-world projects may require extensive data preprocessing, feature engineering, and model tuning.
- More complex architectures and hyperparameter tuning are often necessary for deep learning projects.
- Ensure you have the required libraries installed using pip install pandas matplotlib sci-kit-learn TensorFlow.

Conclusion and Next Steps
In conclusion, this guide underscores Python's pivotal role in data science, offering professionals a versatile and readable platform.
The highlighted libraries showcase Python's extensive ecosystem for efficient data manipulation and advanced analytics. The practical examples illustrate Python's applicability across the data science spectrum. The emphasized advantages of Python, such as its community support and cross-platform compatibility, reinforce its standing as the go-to language. Hence, people like Ned can better somebody's life quickly.
As readers embark on their data science journey, continuous learning, hands-on projects, and community engagement are crucial next steps in mastering this dynamic field, with Python as a steadfast companion. If you also want to master Python, join OdinSchool's Data Science Course to build your career.
Further Learning Resources
- Dive into books such as "Python for Data Analysis" by Wes McKinney and "Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron.
Happy coding!