Top 6 AI Tools Every Data Scientist Must Know | ChatGPT Not Included!

In the grand tapestry of the digital age, data stands as the raw material from which insights are woven, insights that drive innovation, shape strategies, and illuminate the path forward.
Within this vast landscape, data scientists emerge as modern-day sorcerers, armed not with wands and spells but with algorithms and tools that transform data into gold. In this mystical realm of artificial intelligence (AI) and data science, the right tools are the magician's staff, empowering these modern alchemists to distil wisdom from the sea of data.
They have become the navigators of this uncharted territory, steering through waves of information to uncover hidden patterns, predict trends, and conjure insights that guide decision-making. In this blog post, we embark on a journey through the realm of AI tools, revealing the top 6 essential instruments that every data scientist must wield to cast their spells upon data and sculpt it into a narrative of understanding and foresight.
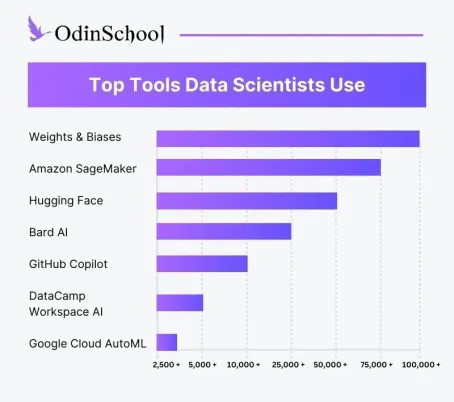
Tool 1 - Weights & Biases
Weights & Biases is a platform that helps data scientists track their experiments and manage their code. Weights & Biases also includes a number of AI tools that can help data scientists with tasks such as model selection, hyperparameter tuning, and error analysis.
Use Case
In this use case, a data scientist is developing a neural network to recognize handwritten digits for a digit recognition application. Uses Weights & Biases (W&B) to track and optimize the training process.
-
Experiment Tracking: The data scientist logs each training run with W&B, keeping a record of different model architectures, learning rates, and batch sizes they experiment with.
-
Visualization: W&B's visualizations help the data scientist monitor the model's accuracy and loss in real time, helping them spot potential issues or improvements quickly.
-
Hyperparameter Optimization: Using W&B, the data scientist efficiently searches for the optimal learning rate and regularization strength, allowing the neural network to converge faster and achieve better accuracy.
-
Collaboration: The data scientist shares experiment results with a colleague. They discuss the impact of different hyperparameters and jointly decide on the best configuration, speeding up the decision-making process.
Tool 2 - Amazon SageMaker
Amazon SageMaker is a cloud-based platform that provides various machine learning tools and services. SageMaker can be used to build, train, and deploy machine learning models at scale.
Use Case
In this use case, a data scientist at an e-commerce company is tasked with building a personalized product recommendation system for the company's website. Uses Amazon SageMaker for the end-to-end development and deployment of the recommendation model.
-
Data Preparation: The data scientist preprocesses user behaviour and product data using SageMaker's built-in tools, ensuring the data is ready for training.
-
Model Selection: Selects a collaborative filtering algorithm from SageMaker's library, leveraging its effectiveness for recommendation tasks.
-
Model Training: The data scientist trains the recommendation model using SageMaker's distributed training capabilities, allowing the model to handle the large user-product interaction dataset.
-
Evaluation: SageMaker helps evaluate the model's performance using historical user interactions and provides metrics like precision at k and mean average precision.
-
Deployment: The trained model is deployed as an API endpoint using SageMaker, allowing the website to provide personalized product recommendations to users in real time.
Tool 3 - Hugging Face
Hugging Face Transformers is a library of pre-trained transformer models. Transformers are a type of neural network that is well-suited for natural language processing tasks such as text classification, question answering, and summarization. Hugging Face Transformers makes it easy for data scientists to use these powerful models without training them from scratch.
Use Case
Imagine a data scientist working on a natural language processing (NLP) project. Need to build a sentiment analysis model for customer reviews.
-
Transformers Library: The data scientist uses Hugging Face's Transformers library to access pre-trained NLP models. A transformer model that is well-suited for sentiment analysis is chosen. This step significantly accelerates the model development process, as it can leverage the latest advancements in NLP without starting from scratch.
-
Model Hub: The data scientist explores the Model Hub to discover community-contributed sentiment analysis models. A model that meets project requirements is found, saving time by using a pre-tuned sentiment analysis model. Can even contribute to the Model Hub, benefiting the NLP community.
{% module_block module "widget_7f21190d-bf5f-4f75-91fc-a706a5343013" %}{% module_attribute "child_css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "definition_id" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "field_types" is_json="true" %}{% raw %}{"image_desktop":"image","image_link":"link","image_mobile":"image"}{% endraw %}{% end_module_attribute %}{% module_attribute "image_desktop" is_json="true" %}{% raw %}{"alt":"Blog-Listing-Ad-_4_","height":300,"loading":"lazy","max_height":300,"max_width":1200,"size_type":"auto","src":"https://odinschool-20029733.hs-sites.com/hubfs/Blog-Listing-Ad-_4_.webp","width":1200}{% endraw %}{% end_module_attribute %}{% module_attribute "image_link" is_json="true" %}{% raw %}{"no_follow":false,"open_in_new_tab":true,"rel":"noopener","sponsored":false,"url":{"content_id":null,"href":"https://www.odinschool.com/datascience-bootcamp","type":"EXTERNAL"},"user_generated_content":false}{% endraw %}{% end_module_attribute %}{% module_attribute "image_mobile" is_json="true" %}{% raw %}{"alt":"Mobile-version-of-blog-ads-_1_-2","height":300,"loading":"lazy","max_height":300,"max_width":500,"size_type":"auto","src":"https://odinschool-20029733.hs-sites.com/hubfs/Mobile-version-of-blog-ads-_1_-2.webp","width":500}{% endraw %}{% end_module_attribute %}{% module_attribute "label" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "module_id" is_json="true" %}{% raw %}132581904694{% endraw %}{% end_module_attribute %}{% module_attribute "path" is_json="true" %}{% raw %}"/OdinSchool_V3/modules/Blog/Blog Responsive Image"{% endraw %}{% end_module_attribute %}{% module_attribute "schema_version" is_json="true" %}{% raw %}2{% endraw %}{% end_module_attribute %}{% module_attribute "smart_objects" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "smart_type" is_json="true" %}{% raw %}"NOT_SMART"{% endraw %}{% end_module_attribute %}{% module_attribute "tag" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "type" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "wrap_field_tag" is_json="true" %}{% raw %}"div"{% endraw %}{% end_module_attribute %}{% end_module_block %}
Tool 4 - Bard AI
Bard AI is a large language model developed by Google AI. It is similar to ChatGPT in that it can be used to generate text, translate languages, and write different kinds of creative content. However, Bard AI is also capable of performing more complex tasks, such as coding, debugging, and research.
Use Case
Let's consider a data scientist working at a market research company. Their task is to analyze customer reviews from various sources to understand consumer sentiment and identify trends. Here's how Bard AI's standout features come into play:
-
Text Analysis Tools: The data scientist uses Bard AI's sentiment analysis tool to analyze large volumes of customer reviews. This tool automatically classifies reviews as positive, negative, or neutral, providing a quick overview of overall sentiment. This feature saves time and allows focus on deeper analysis.
-
Customization: Since the market research company operates in a specific industry, the data scientist customizes Bard AI's entity recognition tool to identify industry-specific terms and entities in the reviews. This customization ensures that the insights extracted are relevant to the company's domain, leading to more accurate results.
Tool 5 - GitHub Copilot
GitHub Copilot is an AI assistant that can help data scientists write code. Copilot is powered by OpenAI's Codex language model, and it can generate code, complete incomplete code, and suggest improvements to existing code.
Use Case
Now, let's follow a data scientist working on a machine learning project. A predictive model for stock prices is being developed.
-
AI-Powered Code Completion: The data scientist writes Python code to preprocess financial data and build machine learning models. GitHub Copilot suggests relevant code snippets for data preprocessing tasks, such as handling missing values, scaling features, and splitting datasets. This accelerates the coding process and reduces manual coding effort.
-
Learning from Developer Patterns: As the data scientist works on the project, GitHub Copilot learns from the patterns in their code. It recognizes that the data scientist often uses specific libraries and follows certain coding conventions. As a result, Copilot provides even more accurate code suggestions over time, aligning with the data scientist's coding style and preferences.
Tool 6 - Google Cloud AutoML
Google Cloud AutoML is a suite of machine learning tools that can help data scientists build and deploy machine learning models without having to write any code. AutoML can be used for a variety of tasks, such as image classification, natural language processing, and fraud detection.
Use Case
Let's follow a data scientist working at an e-commerce company. He is tasked with building a custom recommendation system for personalized product recommendations on the company's website.
-
User-Friendly Interface: The data scientist uses Google Cloud AutoML to create a recommendation model. Assuming that he doesn't have deep expertise in building recommendation systems, but the user-friendly interface guides him through the process. Upload historical user interaction data and product information, select the appropriate recommendation algorithm, and set up training.
-
Automated Training: AutoML takes care of the complex aspects of model training, such as feature engineering and hyperparameter tuning. The data scientist doesn't need to spend weeks experimenting with different algorithms and parameter settings. AutoML automates these tasks, allowing the data scientist to focus on evaluating the model's performance and fine-tuning it for the best recommendations.
Conclusion
In the dynamic world of data science, mastering powerful tools can make all the difference in your journey to becoming a skilled data scientist. The real-world use cases cited here shed light on the transformative impact they can have on your daily work.
However, truly harnessing the potential of these tools requires hands-on experience and guidance. That's where a comprehensive data science course comes in. Through an immersive learning experience, you'll gain the knowledge and skills needed to navigate the intricacies of the essential tools. So, join today.