What is a Data Structure?

In today's competitive and challenging world, data is one of the most powerful tools available to any business or organization that wants to survive and rise to the top. The more information available, the more options and better solutions to problems and obstacles become available.
However, this data has some essential requirements, including keeping the information organized and accessible. All the data in the world will only help a business if it can access it and convert it into an actionable asset.
The data structure is the main part of computer science algorithms by which programmers can handle data well. It plays a vital role in improving the performance of the program or software.
What is Data Structure?
The data structure is a way to store and organize data in a computer system so that we can use the data easily.
Its main operations are given below:-
- Searching – The process of finding an element is called searching. There are two algorithms to complete the search, the first binary search and the second linear search.
- Sorting – The process of arranging the data structure in a particular order is called sorting. There are many algorithms to perform sorting, such as – insertion sort, selection sort, bubble sort, radix sort, etc.
- Insertion – The process of adding elements to a location is called insertion. If the size of a data structure is n, then we can insert only n-1 elements in it.
- Deletion – The process of removing an element is called deletion. We can delete data from any location we want.
- Traversing – Traversing means traversing each data structure element to perform a particular task.
- Merging – Joining two such lists which have the same type of data elements together is called merging. From this, we get a third list.
Characteristics of Data Structure
- Linear or Nonlinear: This is the order characteristic of the data structure. It arranges the data in a sequential form.
- Static or Dynamic: This characteristic defines whether the data's format, size, and memory location remain the same or change over time.
- Time complexity: By this characteristic, we can understand if any algorithm is operated on the data structure, then how much time will be required in any case? (Because the less time the system takes, the more perfect it will be identified)
- Correctness: By this characteristic, we can understand how precisely the data structure is implemented in the interface.
- Space complexity: This characteristic defines how carefully memory usage is maintained for a data structure.
Two Types of Data Structures
- Primitive Data Structures
- Non-primitive Data Structures
- Primitive Data Structure:- Primitive data structure is a data structure that can be operated directly from machine instructions. That is, it is defined by the system and the compiler.
Ex: integer, character, float, boolean (Basically data types)
- Non-primitive data structure:- A primitive data structure is a data structure that cannot be operated by direct machine instructions. These data structures are derived from primitive data structures.
Ex: Array, Linked list, stack, etc.
There are two types of non-primitive data structures:-
- Linear Data Structure
- Non-linear Structure
The linear data structure is a data structure in which data items are stored and arranged in a linear form, with one data item connected to another as a line.
Ex:- array, linked list, queue, stack.
Applications of linear data structures are mainly in application software development.
2. Non-linear data structure
The non-linear data structure is a data structure in which data items are not arranged sequentially. A data item can be associated with any number of other data items.
Ex:-tree, graph.
Applications of non-linear data structures are in Artificial Intelligence and image processing.
{% module_block module "widget_929fb95b-8e55-4f64-9e1f-e8a3eef0d972" %}{% module_attribute "child_css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "definition_id" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "field_types" is_json="true" %}{% raw %}{"image_desktop":"image","image_link":"link","image_mobile":"image"}{% endraw %}{% end_module_attribute %}{% module_attribute "image_desktop" is_json="true" %}{% raw %}{"alt":"Blog-Listing-Ad-Sep-05-2023-07-49-05-0749-AM","height":300,"loading":"lazy","max_height":300,"max_width":1200,"size_type":"auto","src":"https://odinschool-20029733.hs-sites.com/hubfs/Blog-Listing-Ad-Sep-05-2023-07-49-05-0749-AM.webp","width":1200}{% endraw %}{% end_module_attribute %}{% module_attribute "image_link" is_json="true" %}{% raw %}{"no_follow":false,"open_in_new_tab":true,"rel":"noopener","sponsored":false,"url":{"content_id":null,"href":"https://www.odinschool.com/datascience-bootcamp","type":"EXTERNAL"},"user_generated_content":false}{% endraw %}{% end_module_attribute %}{% module_attribute "image_mobile" is_json="true" %}{% raw %}{"alt":"Mobile-version-of-blog-ads-_1_-Sep-05-2023-07-49-13-2894-AM","height":300,"loading":"lazy","max_height":300,"max_width":500,"size_type":"auto","src":"https://odinschool-20029733.hs-sites.com/hubfs/Mobile-version-of-blog-ads-_1_-Sep-05-2023-07-49-13-2894-AM.webp","width":500}{% endraw %}{% end_module_attribute %}{% module_attribute "label" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "module_id" is_json="true" %}{% raw %}132581904694{% endraw %}{% end_module_attribute %}{% module_attribute "path" is_json="true" %}{% raw %}"/OdinSchool_V3/modules/Blog/Blog Responsive Image"{% endraw %}{% end_module_attribute %}{% module_attribute "schema_version" is_json="true" %}{% raw %}2{% endraw %}{% end_module_attribute %}{% module_attribute "smart_objects" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "smart_type" is_json="true" %}{% raw %}"NOT_SMART"{% endraw %}{% end_module_attribute %}{% module_attribute "tag" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "type" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "wrap_field_tag" is_json="true" %}{% raw %}"div"{% endraw %}{% end_module_attribute %}{% end_module_block %}
Classification Of Data Structure at a Glance
Array
An array is a static data structure i.e. we can allocate memory only at compile time and cannot change it at run-time.
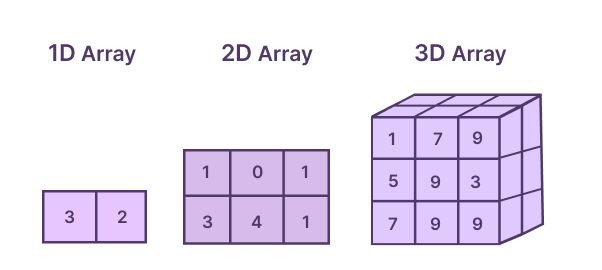
- One-dimensional (1-D) arrays:
Arrays that contain only one subscript are called one-dimensional arrays. It is used to store data in linear form.
- Two-dimensional (2-D) arrays:
The arrays in which there are two subscripts are called two-dimensional arrays. Two-dimensional arrays are also called matrices and tables.
- Multi-dimensional (M-D) arrays:
The arrays which contain more than two subscripts are called Muti-dimensional arrays.
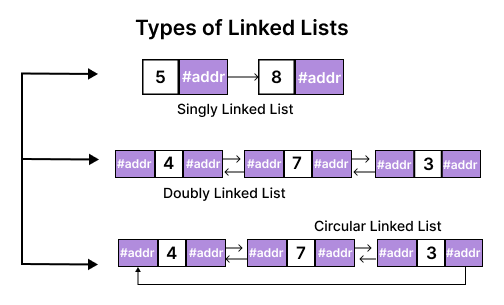
Linked List
- A linked list is a non-primitive, linear data structure.
- A linked list is made up of a group of nodes. Each node has two parts, the first part is the data, and the second is the pointer. The linked list's pointer holds the next node's address. Nodes are used to store the data.
- A linked list is a data structure whose length can be increased or decreased at runtime. That is, it is dynamic.
There are three types of linked lists:-
- Single linked list: It has a one-way direction, and each node of a single linked list has two fields:-
- The first is the field where the data store resides.
- The second is a pointer or link.
- Doubly linked list: It has a two-way direction. Each node of the doubly linked list consists of three parts:-
- In the first part, the data store is kept.
- The second part is the link to the next node.
- The third part is the link to the previous one.
- Circular linked list: Each node in the circular linked list is connected in the form of a circle.
- There is no NULL value at the end of the circular linked list.
In this, the last node is kept containing the address of the first node i.e. the first and last nodes are adjacent.
There are two types of circular linked lists:
1. Single circular linked list
2. Doubly circular linked list.
Queue
The queue is a non-primitive and linear data structure, and it works on the principle of FIFO (first in, first out) i.e. the item which is added first will be removed first, and the item which is last. It is added to it; it will be removed at the end.

Following are the operations performed in Queue:-
Enqueue – When we add an item or element to the queue, then that operation is called enqueue.
Dequeue – When we delete an item from the queue, then that operation is called dequeue.
Peek – This operation is used to get the front element of the queue, and the element is not deleted in it.
isEmpty – This is used to check whether the queue is empty or not. When the queue is empty, it throws an underflow condition.
isFull – It is used to check whether the queue is completely full or not. When the queue is completely full then, it throws the overflow condition.
Different types of Queue:
It is four types, which are given below.
1. Linear Queue – Insertion is done from one end, and deletion is done from the other end. The end from where the insertion is done is called the rear end, and the end from where the deletion is done is called the front end.
2. Circular Queue – In this, all the nodes are presented as a circle. In this, the last element is associated with the first element. It is also called a ring buffer. In the Circular Queue, the item is added from the rear end and removed from the front end.
3. Priority Queue – This is a special type of queue in which each element has a priority associated with it, and it works on the basis of that priority. In this, the element which has the lowest priority is removed first. If the elements have the same priority, then the elements are arranged on the basis of the FIFO principle.
4. Dequeue – The full form of a Dequeue is a double-ended queue. Dequeue is a data structure in which we can add and remove items from both the front and rear ends.
{% module_block module "widget_6747266b-f86c-40df-82b5-a302bb5fd006" %}{% module_attribute "child_css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "css" is_json="true" %}{% raw %}{}{% endraw %}{% end_module_attribute %}{% module_attribute "definition_id" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "field_types" is_json="true" %}{% raw %}{"image_desktop":"image","image_link":"link","image_mobile":"image"}{% endraw %}{% end_module_attribute %}{% module_attribute "image_desktop" is_json="true" %}{% raw %}{"alt":"Blog-Listing-Ad-Sep-05-2023-07-50-01-0933-AM","height":300,"loading":"lazy","max_height":300,"max_width":1200,"size_type":"auto","src":"https://odinschool-20029733.hs-sites.com/hubfs/Blog-Listing-Ad-Sep-05-2023-07-50-01-0933-AM.webp","width":1200}{% endraw %}{% end_module_attribute %}{% module_attribute "image_link" is_json="true" %}{% raw %}{"no_follow":false,"open_in_new_tab":true,"rel":"noopener","sponsored":false,"url":{"content_id":null,"href":"https://www.odinschool.com/datascience-bootcamp","type":"EXTERNAL"},"user_generated_content":false}{% endraw %}{% end_module_attribute %}{% module_attribute "image_mobile" is_json="true" %}{% raw %}{"alt":"Mobile-version-of-blog-ads-_1_-Sep-05-2023-07-50-06-3201-AM","height":300,"loading":"lazy","max_height":300,"max_width":500,"size_type":"auto","src":"https://odinschool-20029733.hs-sites.com/hubfs/Mobile-version-of-blog-ads-_1_-Sep-05-2023-07-50-06-3201-AM.webp","width":500}{% endraw %}{% end_module_attribute %}{% module_attribute "label" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "module_id" is_json="true" %}{% raw %}132581904694{% endraw %}{% end_module_attribute %}{% module_attribute "path" is_json="true" %}{% raw %}"/OdinSchool_V3/modules/Blog/Blog Responsive Image"{% endraw %}{% end_module_attribute %}{% module_attribute "schema_version" is_json="true" %}{% raw %}2{% endraw %}{% end_module_attribute %}{% module_attribute "smart_objects" is_json="true" %}{% raw %}null{% endraw %}{% end_module_attribute %}{% module_attribute "smart_type" is_json="true" %}{% raw %}"NOT_SMART"{% endraw %}{% end_module_attribute %}{% module_attribute "tag" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "type" is_json="true" %}{% raw %}"module"{% endraw %}{% end_module_attribute %}{% module_attribute "wrap_field_tag" is_json="true" %}{% raw %}"div"{% endraw %}{% end_module_attribute %}{% end_module_block %}
Stack
Stack is a special type of linear data structure that works on the principle of LIFO (last in, first out) i.e. the item added last is removed first, and the item added first is added is removed at the end.
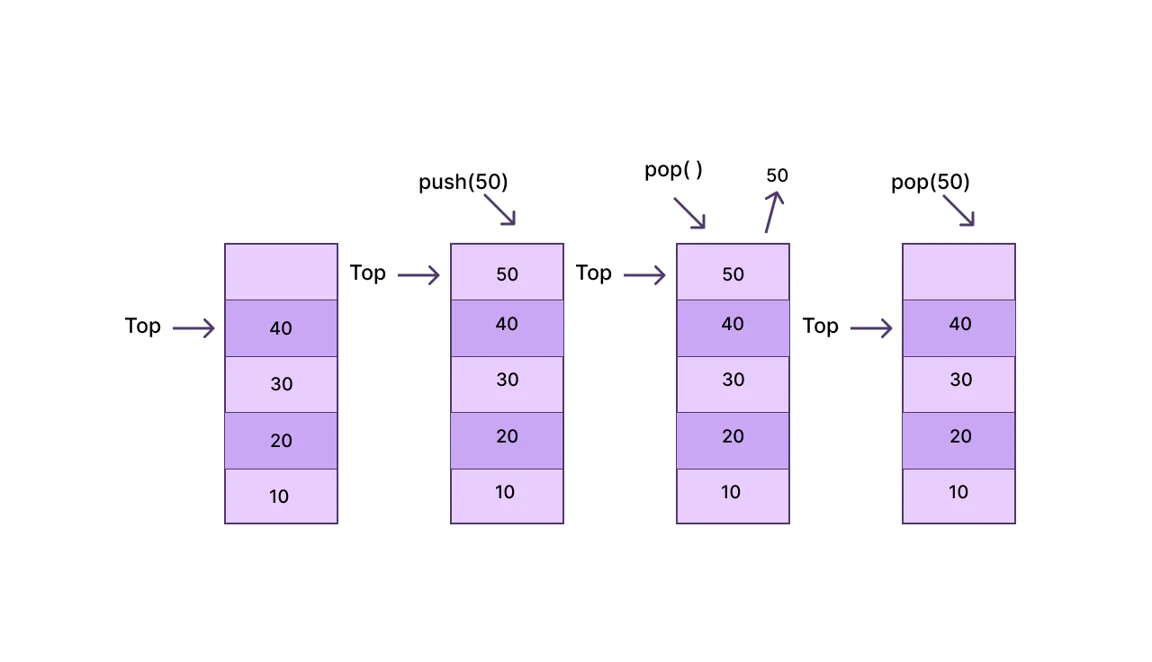
The following operations are performed in the stack:
push() – When the item is inserted in the stack, it is called a push operation, and if the stack is full, there is an overflow condition.
pop() – When an item is deleted from the stack, then this operation is called pop operation. If the stack is empty, then an underflow condition occurs.
We can say that the stack overflows when it is completely full, and we can say it underflows when it is completely empty.
isEmpty() – This operation tells whether the stack is empty or not.
isFull() – This operation tells whether the stack is full or not.
peek() – it returns the element at the given position,
count() – It returns the total number of elements present in the stack.
change() – It changes the element at the given position.
display() – It prints all the elements present in the stack.
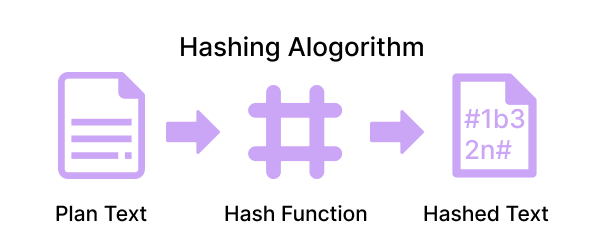
Hashing
The process of generating a fixed length value or key from a set of characters is called hashing. In this process of hashing, a mathematical function is used to generate the value or key.
Or in other words, "the hash value is created by applying a hashing algorithm to the message or data."
Hashing algorithms are also called ‘hash functions’.
We can easily understand hashing with the help of the example:-
Suppose Sidhu sends a message to Simran, then the hash value for this message is generated and encrypted, and this hash value is sent along with the message. When Simran receives this message, he decrypts this message as well as the hash.
After this, Simran generates another hash from the message; if both these hashes are the same, then only secure transmission will be possible.
Graph
We can easily understand the data structure graph on the basis of the following points:-
1. Graph is a non-primitive, non-linear data structure.
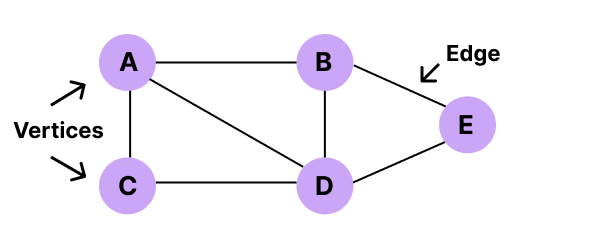
2. Graph is a group of vertices(node). One vertex is connected with another vertex, and the connection between two vertexes is called the edge. The edge acts as a communication link between two nodes.
3. Graph (V, E) is the group where V is the group of vertices and E is the group of edges.
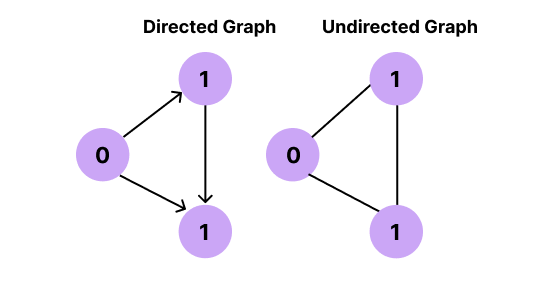
Directed Graph:
A graph in which the edges have a direction is called a directed graph. And such edges are called directed edges. Directed edges are also called acres. Edges in a graph are represented by a line, and if each line carries an arrow mark, then it is called a directed graph. Directed graphs are also called diagrams.
Undirected Graph:
The graph does not have the direction of the edges; that is, there is no arrow mark in it. It is called an Undirected graph.
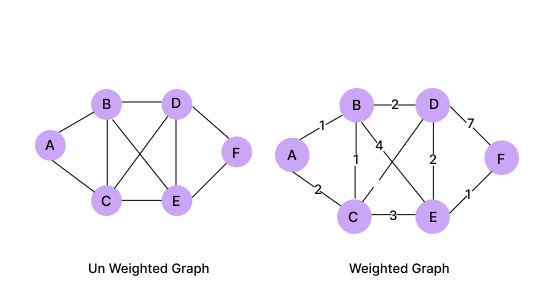
Weighted and Unweighted graphs:
Sometimes graphs have edges; they carry weight. These weights are real numbers. Both directed and undirected graphs can be weighted graphs. Graphs that do not carry weight are called unweighted graphs.
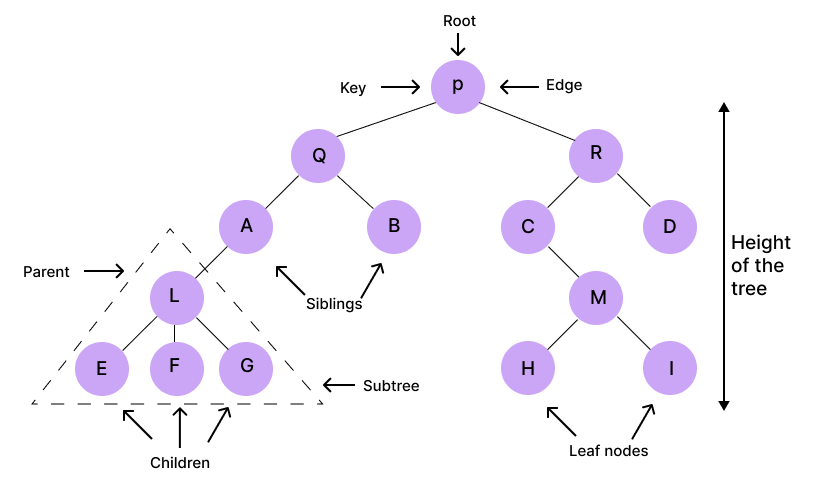
Tree
A tree is a hierarchical data structure that stores information or data in a hierarchical manner.
Structure of a Tree
- A tree is a set of nodes that generally have a hierarchical relationship.
- The tree is a non-linear data structure.
- The tree has a parent-child relationship.
- We call each data item in the tree a node.
- The topmost node in the tree is called the root node.
- A node can have at most one parent. But only the root node has no parent.
- Each node in a tree can have zero or more child nodes.
- Such nodes that do not have child nodes are called leaf nodes or terminal nodes.
- Although the tree always grows upwards, the tree of the data structure always grows downwards.
In the data structure, there are the following types of Tree:
General Tree – A tree in which a node can have either zero child nodes or can have many child nodes. This type of tree is called a general tree.
In this, there is no restriction on child nodes. The topmost node of this tree is called the root node, and it can have many sub-trees.
Binary Tree – Binary means two numbers:- 0 and 1. A binary tree is a tree in which each node can have a maximum of two child nodes. In this, there is a restriction on child nodes because each node in a binary tree can have only two child nodes.
The topmost node in a binary tree is called the root node and has only two sub-trees: the right and left.
Binary Search Tree – Binary search tree is a non-linear data structure in which a node is associated with many nodes. It is a binary tree based on a node.
AVL tree – This is a type of binary tree. It is also called a self-balancing binary search tree. It has extra information, which is called the balance factor.
B-tree – A B-tree is an M-Way (multi-way) tree specially designed for use in disks. A ‘B-tree’ is called a balanced tree.
Applications of Data Structures
Data structures are used in various fields, such as
- Operating systems
- Graphics
- Computer Design
- Blockchain
- Genetics
- Image Processing
- Simulation
Conclusion
Data is the fuel that drives today's commerce engines, and data scientists are in high demand. Since 2012, the demand for data scientists has increased by 650%, and this trend is expected to continue. The data scientist profession is still one of the hottest IT careers today, and you can now get in on the action.
OdinSchool offers an intensive hands-on Data Science Course with placement assistance. It is led by industry experts and provides an industry-vetted curriculum with a particular emphasis on the most in-demand skills.
Connect with a career counsellor to launch your career to new heights!